slUtils = {
{
document.getElementById('widget-tip')?.classList.remove('nojs');
document.getElementById('benchmark-fallback')?.classList.add('nojs');
// Always update CSS content (not just on first create) so hot-reload picks up changes
let style = document.getElementById('sl-shared-styles');
if (!style) {
style = document.createElement('style');
style.id = 'sl-shared-styles';
document.head.appendChild(style);
}
style.textContent = `
.sl-row { display: flex; align-items: center; height: 2.3rem; }
.sl-label { width: var(--sl-label-width, 5rem); flex-shrink: 0; text-align: right; padding-right: 0.75rem; opacity: 0.5; font-size: 0.92em; white-space: nowrap; }
.sl-op { width: 1.3rem; flex-shrink: 0; text-align: right; padding-right: 0.3rem; font-weight: 700; box-sizing: content-box; }
.sl-bits { display: flex; }
.sl-bit { width: 1.5rem; height: 1.8rem; display: inline-flex; align-items: center; justify-content: center; border-radius: 3px; border: 1px solid rgba(37, 99, 235, 0.2); box-sizing: border-box; position: relative; overflow: hidden; transition: background 0.4s ease; }
.sl-val { font-variant-numeric: tabular-nums; }
.sl-val.b1 { font-weight: 700; }
.sl-val.b0 { opacity: 0.35; }
.sl-bit.hl { background: rgba(37, 99, 235, 0.15); }
.sl-val.sl-entering { position: absolute; inset: 0; display: flex; align-items: center; justify-content: center; }
.sl-val.sl-exiting { position: absolute; inset: 0; display: flex; align-items: center; justify-content: center; }
.sl-carry { position: absolute; font-size: 0.55em; font-weight: 700; opacity: 0.7; font-variant-numeric: tabular-nums; transition: all 0.3s ease; }
.sl-ibit { width: 1.5rem; height: 1.8rem; display: inline-flex; align-items: center; justify-content: center; border-radius: 3px; cursor: pointer; user-select: none; font-variant-numeric: tabular-nums; transition: opacity 0.15s; border: 1px solid rgba(37, 99, 235, 0.2); box-sizing: border-box; }
.sl-ibit.b1 { font-weight: 700; }
.sl-ibit.b0 { opacity: 0.35; }
.sl-ibit:hover { opacity: 0.7; }
.sl-ibit.invalid { background: rgba(220, 38, 38, 0.15); border-color: rgba(220, 38, 38, 0.4); opacity: 1; }
.sl-hr { margin-left: calc(var(--sl-label-width, 5rem) + 1.6rem); margin-top: 0.15rem; margin-bottom: 0.15rem; width: calc(8 * 1.5rem); border: none; border-top: 2px solid; opacity: 0.5; }
.sl-calc { margin-left: calc(var(--sl-label-width, 5rem) + 1.6rem); margin-top: 0.4rem; width: calc(8 * 1.5rem); font-family: inherit; font-size: 0.85em; padding: 0.25rem 0; cursor: pointer; border: 1.5px solid currentColor; border-radius: 3px; background: transparent; color: inherit; text-align: center; transition: opacity 0.2s; }
.sl-calc:disabled, .sl-calc.sl-disabled { opacity: 0.35; cursor: not-allowed; }
.sl-toast { margin-left: 0; margin-top: 0.3rem; width: 19.5rem; font-size: 0.8em; color: rgba(220, 38, 38, 0.8); overflow: hidden; opacity: 0; max-height: 0; transition: opacity 0.3s, max-height 0.3s; }
.sl-toast.visible { opacity: 1; max-height: 4rem; }
`;
}
const toBits = n => Array.from({length: 8}, (_, i) => (n >> (7 - i)) & 1);
const wait = ms => new Promise(r => setTimeout(r, ms));
const raf = () => new Promise(r => requestAnimationFrame(r));
function mkBit(v) {
const s = document.createElement('span');
s.className = 'sl-bit';
const t = document.createElement('span');
t.className = `sl-val ${v ? 'b1' : 'b0'}`;
t.textContent = v;
s.appendChild(t);
return s;
}
function mkRow(label, bits, op) {
const r = document.createElement('div');
r.className = 'sl-row';
const l = document.createElement('span');
l.className = 'sl-label';
l.textContent = label;
r.appendChild(l);
const o = document.createElement('span');
o.className = 'sl-op';
o.textContent = op || '';
r.appendChild(o);
const g = document.createElement('div');
g.className = 'sl-bits';
const cells = bits.map(mkBit);
cells.forEach(c => g.appendChild(c));
r.appendChild(g);
return { el: r, lbl: l, opEl: o, bitsDiv: g, cells };
}
function animateBit(cell, newVal) {
while (cell.children.length > 1) cell.removeChild(cell.lastChild);
const old = cell.firstChild;
const neu = document.createElement('span');
neu.className = `sl-val ${newVal ? 'b1' : 'b0'} sl-entering`;
neu.textContent = newVal;
neu.style.opacity = '0';
neu.style.transform = 'translateY(-70%)';
cell.appendChild(neu);
old.className = old.className + ' sl-exiting';
requestAnimationFrame(() => { requestAnimationFrame(() => {
old.style.transition = 'opacity 0.4s ease, transform 0.4s ease';
neu.style.transition = 'opacity 0.4s ease, transform 0.4s ease';
old.style.opacity = '0';
old.style.transform = 'translateY(70%)';
neu.style.opacity = '';
neu.style.transform = 'translateY(0)';
}); });
setTimeout(() => {
if (!cell.isConnected) return;
if (cell.contains(old)) cell.removeChild(old);
neu.className = `sl-val ${newVal ? 'b1' : 'b0'}`;
neu.style.cssText = '';
}, 450);
}
// Cascading addition animation with carry visualization.
// cells: 8 .sl-bit elements already displaying initial values (mask).
// bitsArr: 8-element array of bits to add.
// direction: 'ltr' (carry left, LSB→MSB) or 'rtl' (carry right, MSB→LSB).
async function animateAdd(cells, bitsArr, direction) {
const step = direction === 'ltr' ? -1 : 1;
const start = direction === 'ltr' ? 7 : 0;
const end = direction === 'ltr' ? -1 : 8;
// Corner where carry indicators sit
const crnrLeft = direction === 'ltr' ? '2px' : 'calc(100% - 0.6rem)';
// Edge where carry enters target cell from
const entryLeft = direction === 'ltr' ? 'calc(100%)' : '-0.5rem';
// Direction old value exits toward (for 1+1 carry animation)
const exitTx = direction === 'ltr' ? 'translateX(-0.7rem) scale(0.5)' : 'translateX(0.7rem) scale(0.5)';
// Track effective cell values (updated as carries resolve)
const vals = cells.map(c => {
const v = c.querySelector('.sl-val');
return v ? parseInt(v.textContent) : 0;
});
let carry = 0;
let markerIdx = -1; // which cell has a carry marker
for (let i = start; i !== end; i += step) {
const cell = cells[i];
const a = vals[i];
const b = bitsArr[i];
const sum = a + b + carry;
const result = sum & 1;
const carryOut = sum >> 1;
const nextI = i + step;
const hasNext = nextI >= 0 && nextI < 8;
const hasMarker = markerIdx === i;
let acted = false;
// --- Handle existing carry marker at this cell ---
if (hasMarker) {
const cm = cell.querySelector('.sl-carry');
if (cm) {
// Carry always propagates when marker present (a=1,carry=1 → sum≥2)
// Slide marker toward exit edge and fade
cm.style.left = entryLeft;
cm.style.opacity = '0';
cm.style.transform = 'scale(0.5)';
setTimeout(() => { if (cell.contains(cm)) cell.removeChild(cm); }, 350);
}
markerIdx = -1;
acted = true;
}
// --- Animate cell value change ---
if (a !== result) {
if (carryOut && !hasMarker) {
// 1+1=0+carry: custom animation — 0 slides down, old 1 shrinks toward exit
while (cell.children.length > 1) cell.removeChild(cell.lastChild);
const old = cell.querySelector('.sl-val');
const neu = document.createElement('span');
neu.className = 'sl-val b0 sl-entering';
neu.textContent = 0;
neu.style.opacity = '0';
neu.style.transform = 'translateY(-70%)';
cell.appendChild(neu);
old.className += ' sl-exiting';
requestAnimationFrame(() => { requestAnimationFrame(() => {
old.style.transition = 'opacity 0.35s ease, transform 0.35s ease';
neu.style.transition = 'opacity 0.4s ease, transform 0.4s ease';
old.style.opacity = '0';
old.style.transform = exitTx;
neu.style.opacity = '';
neu.style.transform = 'translateY(0)';
}); });
setTimeout(() => {
if (!cell.isConnected) return;
if (cell.contains(old)) cell.removeChild(old);
neu.className = 'sl-val b0';
neu.style.cssText = '';
}, 450);
} else {
// Simple value change (0→1 slide-down, or 1→0 with marker already handled)
animateBit(cell, result);
}
acted = true;
}
vals[i] = result;
// --- Send carry to next cell ---
if (carryOut && hasNext) {
const nextCell = cells[nextI];
const nextVal = vals[nextI];
// Create carry element entering from near edge
const ce = document.createElement('span');
ce.className = 'sl-carry';
ce.textContent = '1';
ce.style.top = '1px';
ce.style.left = entryLeft;
ce.style.opacity = '0';
nextCell.appendChild(ce);
await raf(); await raf();
if (nextVal === 1) {
// Next cell has 1: carry slides to corner, stays as marker
ce.style.left = crnrLeft;
ce.style.opacity = '0.7';
markerIdx = nextI;
carry = 1;
await wait(400); // carry slide transition is 0.3s
} else {
// Next cell has 0: carry slides to center, grows, replaces 0
const oldV = nextCell.querySelector('.sl-val');
if (oldV) {
oldV.style.transition = 'opacity 0.3s ease';
oldV.style.opacity = '0';
}
ce.style.top = '50%';
ce.style.left = '50%';
ce.style.transform = 'translate(-50%, -50%)';
ce.style.fontSize = '1em';
ce.style.opacity = '1';
await wait(500); // carry grow + fade is 0.3s; extra time so resolved cell is visible before next iteration processes it
// Replace carry with proper sl-val
if (nextCell.contains(ce)) nextCell.removeChild(ce);
if (oldV && nextCell.contains(oldV)) nextCell.removeChild(oldV);
const nv = document.createElement('span');
nv.className = 'sl-val b1';
nv.textContent = '1';
if (nextCell.firstChild) nextCell.insertBefore(nv, nextCell.firstChild);
else nextCell.appendChild(nv);
vals[nextI] = 1;
carry = 0;
}
} else if (acted) {
carry = 0;
await wait(450); // animateBit transition is 0.4s
} else {
carry = 0;
await wait(150); // nothing happened, brief scanning pause
}
}
}
function mkInputRow(label, val, opts) {
const row = document.createElement('div');
row.style.cssText = 'display: flex; align-items: center; height: 2.3rem;';
const labelDiv = document.createElement('div');
labelDiv.style.cssText = 'width: var(--sl-label-width, 5rem); flex-shrink: 0; text-align: right; padding-right: 0.75rem; opacity: 0.5; font-size: 0.92em; white-space: nowrap;';
labelDiv.textContent = label;
row.appendChild(labelDiv);
const opSpacer = document.createElement('div');
opSpacer.style.cssText = 'width: 1.3rem; flex-shrink: 0; text-align: right; padding-right: 0.3rem; font-weight: 700; box-sizing: content-box;';
if (opts.op) opSpacer.textContent = opts.op;
row.appendChild(opSpacer);
const bitsDiv = document.createElement('div');
bitsDiv.style.display = 'flex';
bitsDiv.style.flexShrink = '0';
const bitRuns = [];
for (let i = 0; i < 8; i++) {
const b = (val >> (7 - i)) & 1;
const span = document.createElement('span');
span.className = `sl-ibit ${b ? 'b1' : 'b0'}`;
span.textContent = b;
span.addEventListener('click', () => { opts.toggle(i); });
bitRuns.push(span);
bitsDiv.appendChild(span);
}
row.appendChild(bitsDiv);
const hexWrap = document.createElement('span');
hexWrap.style.cssText = 'margin-left: 0.5rem; opacity: 0.5; font-size: 0.92em; white-space: nowrap; display: flex; align-items: center; flex-shrink: 0;';
if (opts.editable) {
hexWrap.append('(0\u{1d5d1}');
const hexInput = document.createElement('input');
hexInput.type = 'text';
hexInput.maxLength = 2;
hexInput.value = val.toString(16).padStart(2, '0');
hexInput.style.cssText = 'width: 2.5ch; font-family: inherit; font-size: inherit; border: 1.5px solid transparent; border-bottom-color: currentColor; border-radius: 2px; background: transparent; text-align: center; padding: 0; color: inherit; transition: border-color 0.15s; margin-right: -4.5px; margin-left: -2px;';
hexInput.addEventListener('mouseenter', () => { hexInput.style.borderColor = 'currentColor'; });
hexInput.addEventListener('mouseleave', () => { if (document.activeElement !== hexInput) { hexInput.style.borderColor = 'transparent'; hexInput.style.borderBottomColor = 'currentColor'; } });
hexInput.addEventListener('focus', () => { hexInput.style.borderColor = 'currentColor'; });
hexInput.addEventListener('blur', () => { hexInput.style.borderColor = 'transparent'; hexInput.style.borderBottomColor = 'currentColor'; });
hexWrap.appendChild(hexInput);
hexWrap.append(')');
row.appendChild(hexWrap);
// Hide hex display when viewport is too narrow
let hexWidth = 0;
const check = () => {
if (!hexWidth && hexWrap.offsetWidth) hexWidth = hexWrap.offsetWidth;
const fixed = labelDiv.offsetWidth + opSpacer.offsetWidth + bitsDiv.offsetWidth;
const cell = row.closest('.cell-output-display') || row.parentElement;
hexWrap.style.display = (cell.clientWidth >= fixed + hexWidth + 24) ? 'flex' : 'none';
};
const ro = new ResizeObserver(check);
requestAnimationFrame(() => {
const cell = row.closest('.cell-output-display') || row.parentElement;
ro.observe(cell);
check();
});
return { row, bitRuns, hexInput, hexWrap, bitsDiv };
} else {
const hexSpan = document.createElement('span');
hexSpan.textContent = `(0\u{1d5d1}${val.toString(16).padStart(2, '0')})`;
hexWrap.appendChild(hexSpan);
row.appendChild(hexWrap);
// Hide hex display when viewport is too narrow
let hexWidth = 0;
const check = () => {
if (!hexWidth && hexWrap.offsetWidth) hexWidth = hexWrap.offsetWidth;
const fixed = labelDiv.offsetWidth + opSpacer.offsetWidth + bitsDiv.offsetWidth;
const cell = row.closest('.cell-output-display') || row.parentElement;
hexWrap.style.display = (cell.clientWidth >= fixed + hexWidth + 24) ? 'flex' : 'none';
};
const ro = new ResizeObserver(check);
requestAnimationFrame(() => {
const cell = row.closest('.cell-output-display') || row.parentElement;
ro.observe(cell);
check();
});
return { row, bitRuns, hexSpan, hexWrap, bitsDiv };
}
}
// Center the widget's bitstring area relative to the page content column.
// Uses a nearby <p> as proxy for body column width/position, since widgets
// use column:screen and the body column shifts when asides go to margin.
function centerWidget(container) {
const style = getComputedStyle(container);
const lw = parseFloat(style.getPropertyValue('--sl-label-width')) || 5;
const remPx = parseFloat(getComputedStyle(document.documentElement).fontSize);
// Distance from widget left edge to bitstring center
const bsCenterPx = (lw + 1.6 + 6) * remPx; // label + op + half of 12rem bits
let lastPad = -1;
let rafId = 0;
const update = () => {
const cell = container.closest('.cell-output-display') || container.parentElement;
const section = cell.closest('section') || cell.parentElement;
const refEl = section.querySelector('p') || cell;
const cellRect = cell.getBoundingClientRect();
const refRect = refEl.getBoundingClientRect();
const colCenter = refRect.left + refRect.width / 2;
const pad = Math.max(remPx/2, colCenter - bsCenterPx - cellRect.left) | remPx/2;
if (pad !== lastPad) {
lastPad = pad;
container.style.paddingLeft = pad + 'px';
}
};
const scheduleUpdate = () => {
if (!rafId) rafId = requestAnimationFrame(() => { rafId = 0; update(); });
};
const ro = new ResizeObserver(scheduleUpdate);
requestAnimationFrame(() => {
const cell = container.closest('.cell-output-display') || container.parentElement;
const section = cell.closest('section') || cell.parentElement;
const refEl = section.querySelector('p') || cell;
ro.observe(cell);
if (refEl !== cell) ro.observe(refEl);
update();
});
}
return { toBits, wait, raf, mkBit, mkRow, animateBit, animateAdd, mkInputRow, centerWidget };
}Finding peaks with SIMD
code
julia
A couple of years ago, I added a benchmarks page to the documentation for my Peaks.jl package (a Julia package for finding peaks in vector data). When I compared the performance of my Peaks.jl functions against other obvious peak finding implementations, I was shocked to discover that some of the other functions were faster!1 🙀 This completely unacceptable situation was just the encouragement nerd-snipe I needed to develop the new fastest™ peak finding function.2 Considering the relative simplicity of the existing peak finding algorithm, any meaningfully faster solution would have to involve explicit SIMD vectorization.3
TipWhat is SIMD?
SIMD stands for single-instruction, multiple-data. CPUs run software by executing one instruction at a time.4 Normal CPU instructions operate on scalar values (e.g. add one number to another), but many CPUs have SIMD extensions which add specialized instructions that can perform common operations (addition, multiplication, comparison, etc) on vector values (e.g. add 4 pair of numbers). This means the CPU does more work at once, which can be very handy to speed up software! Unfortunately, using SIMD forces a different, less-flexible style of programming: it’s harder/not possible to use branching (think if statements), and SIMD instructions operate on a fixed-width vector (e.g. 4 pair of numbers are always added, and if less than 4 pair are available, special handling or a non-SIMD fallback is needed).
Conveniently, I’ve wanted to learn SIMD for a while, and I just needed a personally relevant, real problem to experiment on. Some features can’t be supported in a SIMD algorithm (e.g. no Missing support)5, but it was non-negotiable that both SIMD and non-SIMD functions maintained the same basic definition of a peak:
A peak MUST be preceded by lesser element(s), MAY be followed by equal element(s), and MUST be ultimately followed by lesser element(s).
A peak where the “largest” element(s) occurs more than once is called a “plateau”. The location of a plateau is defined as the first largest element; this definition allows appending data without altering the location of an existing peak.
I’m using Julia in this post (since I’m describing the algorithm/code from my Peaks.jl package), but the concepts should transfer to any language that allows explicit use of SIMD. We’ll use this signal to work out examples:
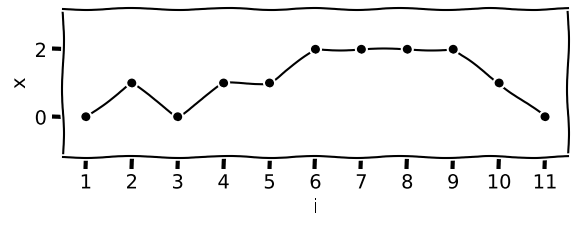
Visually, we can recognize a normal peak at index 2. Next, there is a “false” plateau at index 4, where the signal rises, plateaus, but ultimately rises again (i.e. doesn’t meet the definition for a plateau peak). Finally, there is a true plateau at index 6.
Based on the definition of a peak, we need 3 comparisons for each element. The first part of the function/SIMD loop will need to set up, load the data, and perform the SIMD comparisons; like this:
1offset₋₁ = VecRange{8}(-1)
offset = VecRange{8}( 0)
offset₊₁ = VecRange{8}(+1)
for i in firstindex(x)+1:8:lastindex(x)-1
2 xᵢ₋₁ = x[i + offset₋₁]
xᵢ = x[i + offset]
xᵢ₊₁ = x[i + offset₊₁]
3 rise = bitmask(xᵢ₋₁ < xᵢ)
fall = bitmask(xᵢ₊₁ < xᵢ)
flat = bitmask(xᵢ₊₁ == xᵢ)
# peak identification happens here
end- 1
-
Define SIMD ranges to use as offsets when loading signal elements into SIMD registers.6 These are SIMD specific equivalents of normal ranges (e.g.
VecRange{8}(-1)is functionally equivalent to-1:6). - 2
-
Load (8) signal elements from a range of indices into special SIMD vector registers (e.g. during the first loop,
xᵢ₋₁will load elements1:8fromx,xᵢ₋₁ == x[2 .+ -1:6]).7 - 3
-
The comparisons produce SIMD vectors holding 8
Bools, each of which holds the result (trueorfalse) of a single comparison. Thebitmaskfunction converts eachBoolin the vector into a single bit1or0in a byte (or a larger/wider bitset—a set of bits). Since many CPUs have native hardware support for 64- or 32-bit values, we can later process many more elements/peaks at a time using bitwise and other basic math operators.
TipWhat are bitwise operators?
Bitwise operators are functions (compiled to single CPU instructions) that are focused on manipulating the bits in a value/bitset; most bitwise operators apply logical operations to every bit in a bitset at once. There are bitwise operators for all common logic operations: AND (operator symbol is &), OR (|), NOT (~), etc. Some other operators include left (<<) and right (>>) shifts, which add a number of 0 bit(s) before the least-significant bit (LSB) or after the most-significant bit (MSB), and drop the extra bit(s), e.g. 0b00010101 >> 1 shifts 0b00010101 right by one bit, resulting in 0b00001010.
Bitwise operations normally affect every bit the same way, but sometimes this is undesirable. A common technique is the use of “bitmasks” to control which bit(s) in a set should or shouldn’t be changed by the code. The only difference between a bitmask and a bitset is purpose/intent.
Using the above code on our example signal produces the following bitsets for the three comparisons:
# results shown as a bitstrings
julia> rise = bitmask(xᵢ₋₁ < xᵢ)
0b00010101
julia> fall = bitmask(xᵢ₊₁ < xᵢ)
0b10000001
julia> flat = bitmask(xᵢ₊₁ == xᵢ)
0b01110100Bit ordering in bitsets follows index ordering, such that the least-significant bit (LSB) in a bitset corresponds to the lowest index in that slice of data. Bitstrings are printed most-significant bit (MSB) to LSB, from left-to-right, so the LSB is the rightmost digit.
We know from looking at the signal plot that there are peaks at indices 2 and 6, which means that by the end of our SIMD loop, we should have a bitset with set (1/true) bits at 1 and 5, 0b00010001.8 Study the three bitsets, and you might notice that different approaches are needed to identifying peaks and plateaus.
For normal peaks, every given bit position in rise and fall corresponds to a matched scalar comparison, xᵢ₋₁ < xᵢ and xᵢ₊₁ < xᵢ, for a given i. Normal peaks must have the same set bits in rise AND fall to indicate a peak (i.e. the previous and next elements are less than the current element). Using a bitwise & will produce set bits only if both bits in the pair are set (1/true). So, the simple equation rise & fall will keep only those matched bits, and all other bits will be cleared; for our signal, bit 1 is the only set bit in both rise and fall, resulting in 0b00000001. One peak identified, one peak to go.
Unfortunately, identifying plateaus is trickier. After the normal peaks are identified with rise & fall, fall can be right shifted to align the signal dips with the ends of plateaus. But the set bits in rise and fall for the beginning and end of plateaus will still not be aligned (because the flat part of a plateau might run for multiple elements), so a simple combination like rise & flat & fall won’t work: the same bits might be set in rise and flat, but the set bit in fall could be later.
Every plateau will have a bit run (one or more consecutively set bits, if the plateau has multiple equal values) where the run’s LSB is set in rise and the run’s MSB is set in fall. Multiple plateaus might be present in a flat bitset, and the LSB of each bit run is that peak’s location (bit 5 in our example flat).
We can filter “false” plateaus from flat by first clearing any bit runs that don’t have a set bit in rise matching the start (LSB) bit of the run. Next, clear any bit runs that don’t have a set bit in fall matching the end (MSB) bit of the run. Finally, clear all the remaining bits in flat except for each run’s LSB. We’ll need a few bitwise focused functions to filter the flat bitset as described:
- Functions to clear bit runs that don’t begin or end with an LSB/MSB mask
lsb_mask(0b01110100,0b00010101) ==0b01110100msb_mask(0b01110100,0b01000000) ==0b01110000
- A function to clear all bits except for the (potentially multiple) local LSB of bit runs (e.g.
run_lsb(0b01110) ==0b00010)
Masking bit runs with the run LSB
This function can clear any bit runs in flat that don’t begin with a set bit in rise: bits & ~(bits + mask). The premise is that adding the LSB of any bit run will (by carrying) invert all previously set bits in the run. So, by adding the LSB of only the bit runs we want and then inverting the bitset, we get a bitmask that can be used with an AND op to clear all unwanted bit runs.
You can click on the bits in the bits and mask bitstrings, or change the hex for the byte! Watch how the function clears bit runs that don’t have their LSB set in the mask.
Masking bit runs with the run MSB
I originally didn’t have a complete understanding of the problem space, and missed the importance of carrying (particularly carry direction) to generalize the LSB mask function for MSB masks. I made do with bitreverse operations,9 but the downside was 3 relatively10 expensive bitreverse calls. Off-and-on for several years, I thought about how to better solve this, until I recently finally connected the dots that carrying and carry direction were the core of the problem. With the proper language to describe what I needed, some research led me to adder algorithms. With a little prompting, Claude produced a reverse-carry adder based on the Kogge-Stone algorithm, but using right shifts.11
That accomplished, we can substitute the reverse-carry adder into the same equation used for the LSB mask: bits & ~(bits ⊞ mask), where I’m using ⊞ as the symbol for the reverse-carry adder. The new reverse-carry function is ~2x faster than the original bitreverse based function!12 This new function is a direct corollary of the last function: it can clear any bit runs in flat that don’t end with a set bit in fall.
Calculating the LSB of bit runs
This function can be achieved with x & ~(x << 1). It is based on the fact that the LSB of every bit run is preceded by an unset bit (or will be after a left shift). Zeros become ones when inverted, so after shifting and inverting, the only set bits in both the original and manipulated bitset are the LSB of each bit run. Calling this function on a flat bitmask (that we’ve already filtered to only contain real plateaus) gives us the plateau locations.
Full algorithm
With the new bit-twiddling functions, the complete (ish) SIMD algorithm looks something like:
I’m glossing over the fussy auxiliary code to handle signal lengths that don’t work with the 8 element chunking, and plateaus that span multiple bytes/words.
offset₋₁ = VecRange{8}(-1)
offset = VecRange{8}( 0)
offset₊₁ = VecRange{8}(+1)
for i in firstindex(x)+1:8:lastindex(x)-1
xᵢ₋₁ = x[i + offset₋₁]
xᵢ = x[i + offset]
xᵢ₊₁ = x[i + offset₊₁]
rise = bitmask(xᵢ₋₁ < xᵢ)
fall = bitmask(xᵢ₊₁ < xᵢ)
flat = bitmask(xᵢ₊₁ == xᵢ)
1 peaks = rise & fall
2 fall >>= 1
3 flat = runs_lsb_mask(flat, rise)
flat = runs_msb_mask(flat, fall)
4 peaks |= run_lsb(flat)
end- 1
- Capture normal peaks
- 2
-
Right shift
fallbitmask to align signal dips with the end of plateaus - 3
-
Clear bit runs that don’t begin or end with set bits in
riseandfall - 4
-
Add plateau locations to
peaks.
Ironically, the code using explicit SIMD was the most straightforward part of the code! Instead, the bitwise manipulation after the SIMD was the trickiest part. In the full SIMD algorithm, I use a pre-allocated BitVector to store the peaks bitsets. Using a BitVector has the double benefit of taking the peaks bitsets directly13 (without needing to convert its representation) and avoiding allocations in the core loop.
Benchmarks
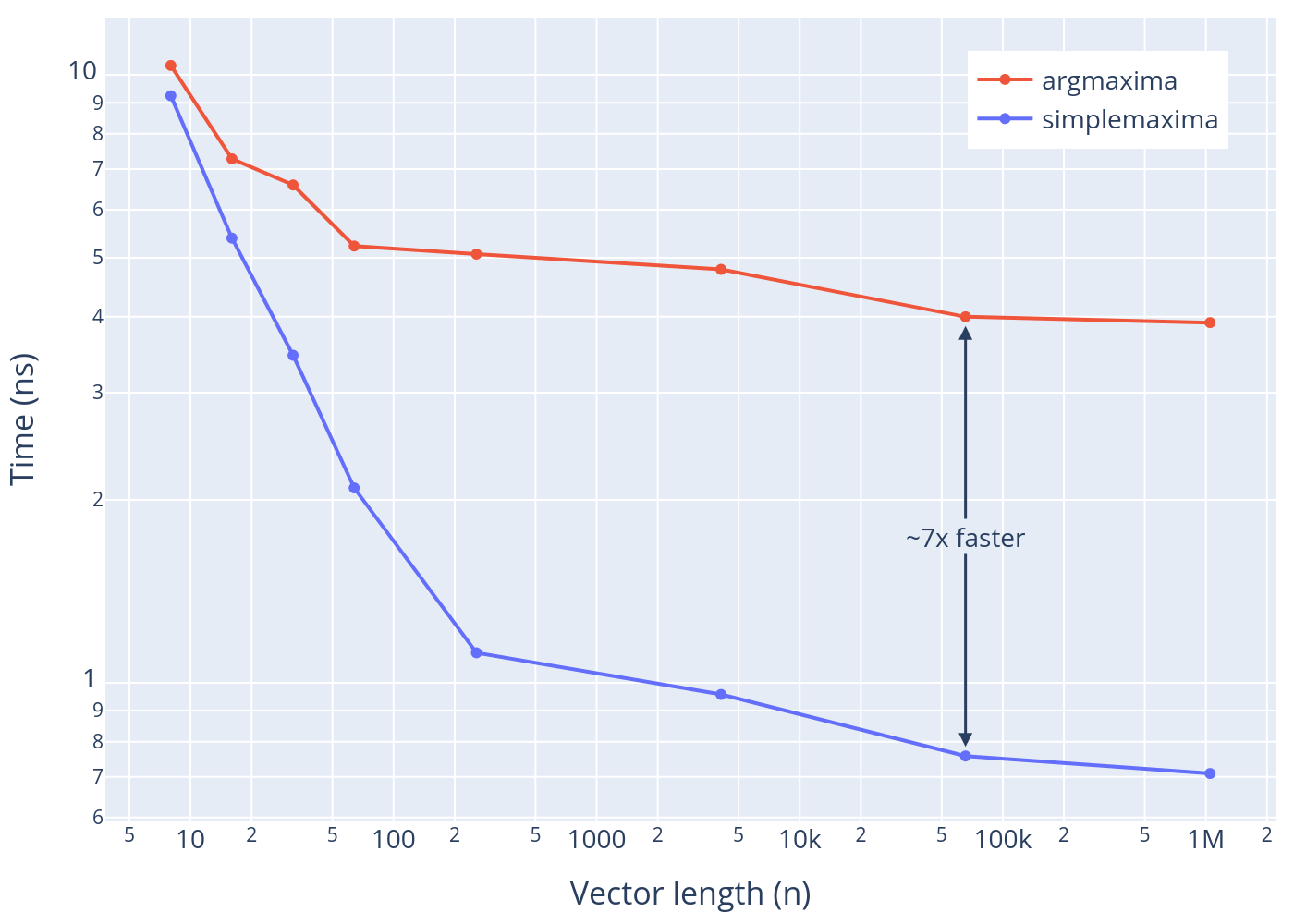
How much faster is the SIMD simplemaxima compared to the scalar argmaxima? Using random (normal) data, here’s the average time per peak for each function for different signal lengths. Check out the benchmarks page for more benchmark results.
Footnotes
These comparisons aren’t completely apples-to-apples, and technically disfavor Peaks.jl functions, which have a larger feature set. In particular, none of the compared functions detect plateau peaks.↩︎
Even though I have never needed faster peak finding, or used peaks in a real-time/performance sensitive context 🙄↩︎
Many compilers, including Julia, can auto-vectorize simple/recognizable code patterns. More complex code must be intentionally and manually refactored to explicitly use SIMD.↩︎
I realize that’s not strictly true with superscalar processors; don’t @ me.↩︎
I decided the
strictkeyword argument and larger window sizes were too difficult and/or not possible to support.↩︎Registers are where CPUs store data for instructions to immediately use.↩︎
Not all hardware will support a so-called vector “width” of e.g. 8 double-precision floats (which would be 512 bits wide). SIMD.jl and LLVM are very helpfully papering over differences between the code and what is actually supported by the hardware.↩︎
Given the definition of a peak, the first possible peak location is at index 2, so the first bit corresponds to that index.↩︎
bitreversereverses the order of a bitset, e.g.0b01110100becomes0b00101110. By reversing thebitsandmask, we can use theruns_lsb_maskfunction to achieve the desired behavior:↩︎bitreverse( runs_lsb_mask( bitreverse(bits), bitreverse(mask) ) )The
bitreverseing took all of 7% of the SIMD function runtime!!↩︎I also realized that the lack of this operation (reverse-carry adder) was the only major function/algorithmic gap blocking support for larger window widths.↩︎
Otherwise there’s not much point. The perfect™ abstraction doesn’t matter if its slow or inconvenient.↩︎
Unfortunately this does require accessing/using
BitVectorinternals.↩︎